ETL PROCESS (Step 2)
(Extraction, Transform, Load)
EXTRACTION PROCESS:
The datasets were extracted from BigQuery, which is a fully managed serverless data warehouse and analytics platform offered by Google Cloud. The datasets used for this project come from diverse source systems. They are the following:
1.Cyclistic Data:
The main dataset used in the query is the bigquery-public-data.new_york_citibike.citibike_trips table, which represents the Cyclistic bike trips data. This dataset contains information about bike trips, including start and end stations, trip duration, and user types.
2.Census Bureau US Boundaries:
the dataset includes a wide range of geospatial boundaries and demographic information at various administrative levels within the United States. These boundaries can be used to define regions and analyze data based on different geographic units.
3.Weather Data: The query also incorporates weather data from the bigquery-public-data.noaa_gsod.gsod20* table. It joins the weather information based on matching dates (start times of bike trips) and the WBAN identifier '94728'. This allows the analysis to include weather-related attributes such as temperature, wind speed, and precipitation.
4.Cyclistic NYC zip codes dataset: This dataset likely includes information specifically related to zip codes within New York City.
TRANSFORMATION PROCESS: BigQuery SQL from Google
SELECT
TRI.usertype,
ZIPSTART.zip_code AS zip_code_start,
ZIPSTARTNAME.borough borough_start,
ZIPSTARTNAME.neighborhood AS neighborhood_start,
ZIPEND.zip_code AS zip_code_end,
ZIPENDNAME.borough borough_end,
ZIPENDNAME.neighborhood AS neighborhood_end,
DATE_ADD(DATE(TRI.starttime), INTERVAL 5 YEAR) AS start_day,
DATE_ADD(DATE(TRI.stoptime), INTERVAL 5 YEAR) AS stop_day,
WEA.temp AS day_mean_temperature,
WEA.wdsp AS day_mean_wind_speed,
WEA.prcp day_total_precipitation,
ROUND(CAST(TRI.tripduration / 60 AS INT64), -1) AS trip_minutes,
COUNT(TRI.bikeid) AS trip_count
Select Statement Description:
(TRI.usertype: This column represents the user type, indicating whether the customer is a subscriber or a customer who makes occasional rides.
ZIPSTART.zip_code AS zip_code_start: This column extracts the zip code of the starting location of each bike trip.
ZIPSTARTNAME.borough borough_start: This column retrieves the borough (e.g., Manhattan, Brooklyn) associated with the starting zip code.
ZIPSTARTNAME.neighborhood AS neighborhood_start: This column fetches the neighborhood within the starting zip code area.
ZIPEND.zip_code AS zip_code_end: This column extracts the zip code of the ending location of each bike trip.
ZIPENDNAME.borough borough_end: This column retrieves the borough associated with the ending zip code.
ZIPENDNAME.neighborhood AS neighborhood_end: This column fetches the neighborhood within the ending zip code area.
DATE_ADD(DATE(TRI.starttime), INTERVAL 5 YEAR) AS start_day: This column adds 5 years to the start date of each bike trip, providing the adjusted start day.
DATE_ADD(DATE(TRI.stoptime), INTERVAL 5 YEAR) AS stop_day: This column adds 5 years to the end date of each bike trip, providing the adjusted stop day.
WEA.temp AS day_mean_temperature: This column retrieves the mean temperature for the day of each bike trip from the weather data (WEA table).
WEA.wdsp AS day_mean_wind_speed: This column retrieves the mean wind speed for the day of each bike trip from the weather data.
WEA.prcp AS day_total_precipitation: This column retrieves the total precipitation for the day of each bike trip from the weather data.
ROUND(CAST(TRI.tripduration / 60 AS INT64), -1) AS trip_minutes: This column calculates the trip duration in minutes by dividing the trip duration (in seconds) by 60 and rounding the result to the nearest 10-minute interval.
COUNT(TRI.bikeid) AS trip_count: This column counts the number of bike trips for each combination of the selected columns.)
FROM
`bigquery-public-data.new_york_citibike.citibike_trips` AS TRI
FROM Clause Description:
(In the provided SQL query, the FROM clause specifies the table bigquery-public-data.new_york_citibike.citibike_trips and assigns it an alias TRI. This indicates that the subsequent operations in the query will be performed on this table.)
INNER JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` ZIPSTART
ON ST_WITHIN(
ST_GEOGPOINT(TRI.start_station_longitude, TRI.start_station_latitude),
ZIPSTART.zip_code_geom)
INNER JOIN descriptions:
(In the provided SQL query, the INNER JOIN clause is used to combine the citibike_trips table with the zip_codes table based on a spatial relationship. The condition ST_WITHIN checks if the start station coordinates from the citibike_trips table are within the zip code boundaries in the zip_codes table.)
INNER JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` ZIPEND
ON ST_WITHIN(
ST_GEOGPOINT(TRI.end_station_longitude, TRI.end_station_latitude),
ZIPEND.zip_code_geom)
(In this part of the SQL query, an INNER JOIN is used to combine the citibike_trips table with the zip_codes table from the geo_us_boundaries dataset. The join is performed based on a spatial relationship using the ST_WITHIN function.)
INNER JOIN
`bigquery-public-data.noaa_gsod.gsod20*` AS WEA
ON PARSE_DATE("%Y%m%d", CONCAT(WEA.year, WEA.mo, WEA.da)) = DATE(TRI.starttime)
(In this part of the SQL query, an INNER JOIN is used to combine the citibike_trips table with the weather data from the noaa_gsod dataset. The join is based on matching dates.
The %Y%m%d format is a commonly used date format specifier known as a date format string. It represents the year (%Y), month (%m), and day (%d) in a specific order.)
INNER JOIN
`Mydataset.zip_codes` AS ZIPSTARTNAME
ON ZIPSTART.zip_code = CAST(ZIPSTARTNAME.zip AS STRING)
(In this part of the SQL query, an INNER JOIN is used to combine the existing data with additional information from the zip_codes table. This join is based on matching zip codes.)
INNER JOIN
`Mydataset.zip_codes` AS ZIPENDNAME
ON ZIPEND.zip_code = CAST(ZIPENDNAME.zip AS STRING)
In this part of the SQL query, an INNER JOIN is used to combine the existing data with the zip_codes table from the Mydataset dataset. The zip_codes table is given an alias ZIPENDNAME for convenience.
WHERE
WEA.wban = '94728'
AND EXTRACT(YEAR FROM DATE(TRI.starttime)) BETWEEN 2014 AND 2015
(In this part of the SQL query, we have a WHERE clause that includes two conditions for filtering the data:
WEA.wban = '94728': This condition filters the data based on the value of the wban column in the WEA table. It selects only the rows where the wban value is equal to '94728'.
EXTRACT(YEAR FROM DATE(TRI.starttime)) BETWEEN 2014 AND 2015: This condition filters the data based on the year extracted from the starttime column in the TRI table. It selects only the rows where the year falls between 2014 and 2015, inclusive.)
GROUP BY
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13
In this part of the SQL query, the GROUP BY clause is used to group the selected columns in the dataset. The numbers 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, and 13 represent the positions of the columns in the SELECT statement.
By including the GROUP BY clause with these numbers, the query will group the dataset based on these specific columns. This means that the data will be aggregated and summarized according to the unique combinations of values in these columns.
Conclusion:
The transformations performed in this SQL query included the following transformation processes:
1.Joining Tables: You performed multiple INNER JOIN operations to combine the citibike_trips table with other tables (zip_codes and noaa_gsod) based on specific conditions. These joins allowed you to merge different datasets together, incorporating additional information from related tables.
2.Filtering: The WHERE clause with conditions like WEA.wban = '94728' and EXTRACT(YEAR FROM DATE(TRI.starttime)) This reduced the dataset to only include rows that met the specified conditions.
3.Column Selection: The SELECT statement specified which columns to include in the final dataset. By selecting specific columns, you transformed the data by narrowing down the information to only the desired attributes for analysis.
4.Aggregation: The GROUP BY clause with the numbers 1, 2, 3, ..., 13 grouped the dataset based on multiple columns. This allowed you to aggregate the data and perform calculations such as counting trips (COUNT(TRI.bikeid)) and generating mean values (ROUND, COUNT).
Overall, these transformations involved joining tables, filtering the data, selecting specific columns, and aggregating the results. These steps helped transform the raw data into a more structured and meaningful dataset that can be analyzed and interpreted to gain insights about customer behavior and patterns.
LOAD PROCESS
After the data was transformed, it was saved as a CSV and loaded it into a designated target system, such as a data warehouse or a specific database. This final loaded dataset serves as the foundation for visualization and analysis in the next phase of the project. The final loaded dataset has 14 columns and 1,000,000 rows. Due to the large dataset, an image of the dataset has been provided.
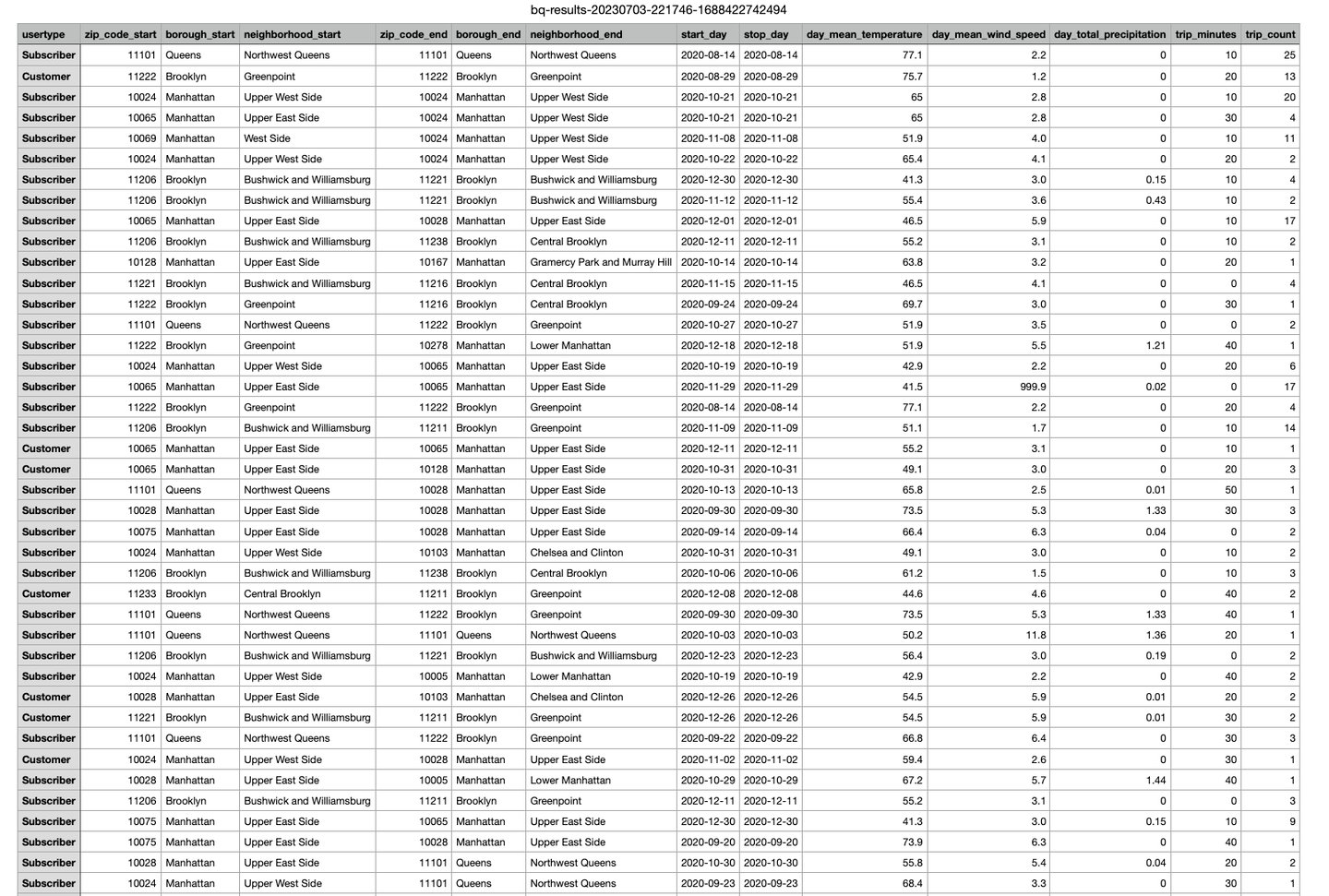
Next, I utilized the transformed dataset and leveraged Tableau for visualization and analysis purposes.